







依據歐盟施行的個人資料保護法,我們致力於保護您的個人資料並提供您對個人資料的掌握。 我們已更新並將定期更新我們的隱私權政策,以遵循該個人資料保護法。請您參照我們最新版的 隱私權聲明。
本網站使用cookies以提供更好的瀏覽體驗。如需了解更多關於本網站如何使用cookies 請按 這裏。
Keep Spinning
16.03
2025
LLM 模型參數量越大越好嗎?企業導入成本居高不下?
LLM模型參數量越大越好嗎?企業導入成本居高不下?
在大語言模型(LLM)快速發展的今天,「參數越大效果越好」成了許多企業選型時的直覺認知。但實際上,這樣的觀念不僅未必正確,甚至可能導致企業投入過多資源卻效果不彰。
為了解開這個迷思,偲倢科技針對數個熱門模型進行測試,選擇 100B 以下的參數量進行測試,並全數透過地端部署方式運行,更貼近企業的實際使用場景。

測試題材:為什麼選擇「114 年學測國綜選擇題」?
重點不在於大語言模型在試卷的答題分數,而是為了更嚴謹地驗證語言模型的核心「中文」理解能力。

圖1:偲倢科技選擇學測國文選擇題測試 LLM 模型效果主要考量是中文應用情境且具明確標準;偲倢科技整理製圖
這類標準化的語文測驗題型,具備三項重要優勢,使其成為絕佳的模型能力測評素材:
- 真實語言理解能力的壓力測試
學測國文涵蓋主旨判讀、語境推論、隱喻解析等多層次的語意理解任務,這些能力與企業實際應用中的知識搜尋、智慧客服、自動摘要等任務高度對應。
對於以中文為主要溝通語言的台灣企業而言,語言模型能否穩定處理中文語意並做出正確推理,將直接影響導入成效與商業價值。因此,中文效能應是企業選型初期的首要考量,避免後續部署仍需大量調整所帶來的成本風險。
對於以中文為主要溝通語言的台灣企業而言,語言模型能否穩定處理中文語意並做出正確推理,將直接影響導入成效與商業價值。因此,中文效能應是企業選型初期的首要考量,避免後續部署仍需大量調整所帶來的成本風險。
- 固定題型、明確標準
相同題組讓不同模型在可比條件下進行作答,避免主觀評分誤差,真正比的是語言推理與理解實力。
- 無領域偏誤,評估泛用性
相較於醫療、法律等專業語料,國文測驗來自自然語言脈絡,能有效測試模型在陌生語境與非特定領域下的理解表現,是衡量中文 LLM 泛用性的重要指標。
模型實測結果揭示:中參數模型反而更穩定
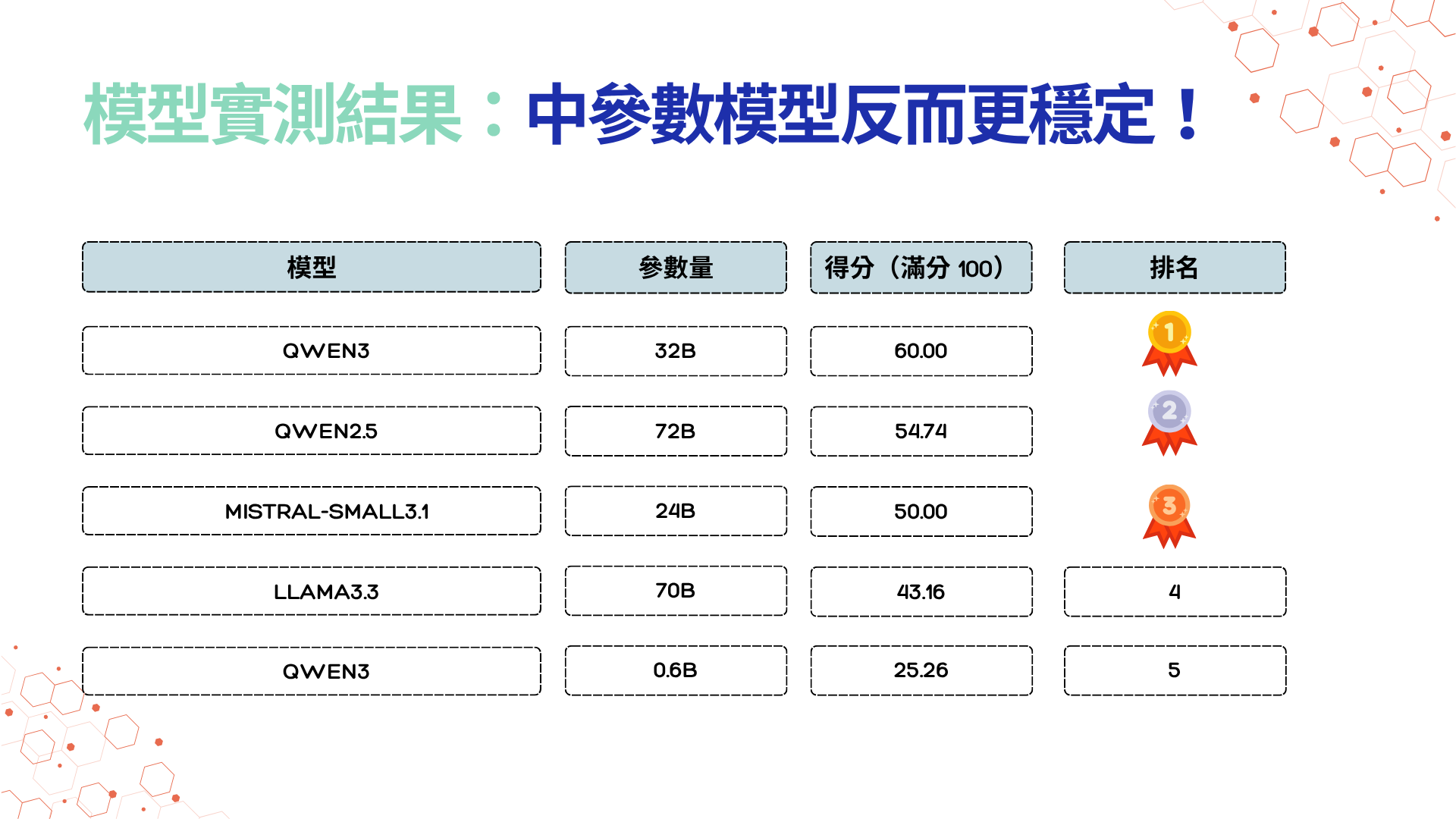
圖2:LLM 模型各參數實測效果;偲倢科技整理製圖
1. 大參數 ≠ 高效能
本次測試中,Qwen3 32B 成為最大贏家,表現超越 Qwen2.5(72B)與 LLaMA3.3(70B),再次證實:模型參數量並非效能保證,盲目追求大型模型只會增加 GPU 規格需求、推論成本與部署複雜度,卻未必帶來效能提升。
此外,大語言模型的研發與升級速度極快,新一代模型往往在中等參數規模下就能展現明顯優勢。
企業若投入高成本部署超大型模型,反而可能在短時間內就因模型汰換而面臨資源浪費。
因此,企業導入 LLM 時,應關注部署架構是否具備彈性與更新能力,能否快速替換或升級模型版本,將成為導入成功的關鍵。
唯有打造模組化、可即時更新的推論框架,才能在模型快速演進的趨勢中維持競爭力與成本效益。
2. 地端部署,更能反映真實應用效能
所有模型測試皆於本地伺服器完成,不依賴雲端 API,企業能夠完整掌控模型推理效能與延遲表現,且滿足資料隱私要求,合規風險低,同時更貼近企業實際運行場景,結果具參考價值。
3. 成本效益,決定部署可行性與持續性
一般而言選用大型模型意味著需要更高階的 GPU 硬體與能源成本,若在企業選用雲端的方案將產生更高的推論費用,且存在部署管理和維運的難度。中參數模型已能支撐高複雜度語言任務,是企業初期導入的高性價比選項。
本次測試中,Qwen3 32B 成為最大贏家,表現超越 Qwen2.5(72B)與 LLaMA3.3(70B),再次證實:模型參數量並非效能保證,盲目追求大型模型只會增加 GPU 規格需求、推論成本與部署複雜度,卻未必帶來效能提升。
此外,大語言模型的研發與升級速度極快,新一代模型往往在中等參數規模下就能展現明顯優勢。
企業若投入高成本部署超大型模型,反而可能在短時間內就因模型汰換而面臨資源浪費。
因此,企業導入 LLM 時,應關注部署架構是否具備彈性與更新能力,能否快速替換或升級模型版本,將成為導入成功的關鍵。
唯有打造模組化、可即時更新的推論框架,才能在模型快速演進的趨勢中維持競爭力與成本效益。
2. 地端部署,更能反映真實應用效能
所有模型測試皆於本地伺服器完成,不依賴雲端 API,企業能夠完整掌控模型推理效能與延遲表現,且滿足資料隱私要求,合規風險低,同時更貼近企業實際運行場景,結果具參考價值。
3. 成本效益,決定部署可行性與持續性
一般而言選用大型模型意味著需要更高階的 GPU 硬體與能源成本,若在企業選用雲端的方案將產生更高的推論費用,且存在部署管理和維運的難度。中參數模型已能支撐高複雜度語言任務,是企業初期導入的高性價比選項。
實際導入關鍵:選對模型比模型大小更重要
圖3: 偲倢科技建議企業進行評估時需考慮:合適的模型參數量、貼近實際運行場景並考量部署的長期成本效益;偲倢科技整理製圖
這次測試不僅是模型效能比較,更提供企業以下參考:
- 模型的語言理解能力,是客服、知識檢索、自動摘要等任務的共同基礎
- 真實部署環境下的效能,才是真正可落地的價值依據
- 選擇合適的模型架構與參數規模,遠比單純追求最大參數更具意義。
想為企業導入 LLM,卻不知道從哪一步開始?
偲倢科技推出的 Edgestar 提供:
- 硬體配置建議與性能實測報告
- 地端部署管理工具與顧問服務
- 不同任務下的效能報告與建議
立即聯繫 ➜讓 LLM 真正為企業所用!💡
偲倢科技推出的 Edgestar 提供:
- 硬體配置建議與性能實測報告
- 地端部署管理工具與顧問服務
- 不同任務下的效能報告與建議
立即聯繫 ➜讓 LLM 真正為企業所用!💡