







依據歐盟施行的個人資料保護法,我們致力於保護您的個人資料並提供您對個人資料的掌握。 我們已更新並將定期更新我們的隱私權政策,以遵循該個人資料保護法。請您參照我們最新版的 隱私權聲明。
本網站使用cookies以提供更好的瀏覽體驗。如需了解更多關於本網站如何使用cookies 請按 這裏。
Keep Spinning
16.03
2025
開源 LLM Tool Call 支援實測:選對第一步,讓 AI 真正進入企業流程
開源 LLM Tool Call 支援實測:選對第一步,讓 AI 真正進入企業流程
在企業導入大型語言模型 (LLM)的過程中,關鍵不只是模型能力有多厲害,更重要的是是否具備實際應用的可行性,以及是否能順利整合至現有系統中。
尤其當模型從「語意理解」轉向「任務執行」角色時,Tool Call 能力已成為判斷其商業價值的關鍵門檻。
Tool Call 不僅代表模型能理解指令,更代表能主動啟用工具,查詢資訊,或執行操作。換言之,這項能力是 LLM 能否進入企業工作流程、承擔執行任務的重要指標。

透過真實任務檢驗模型的實戰能力:LLM「能否落地」的四個關鍵能力
偲倢的 RD 團隊設計了四個測試項目,聚焦在企業導入初期最常見、也最具實用價值的場景。這些項目不只是功能測試,更對應真實的業務流程整合需求:
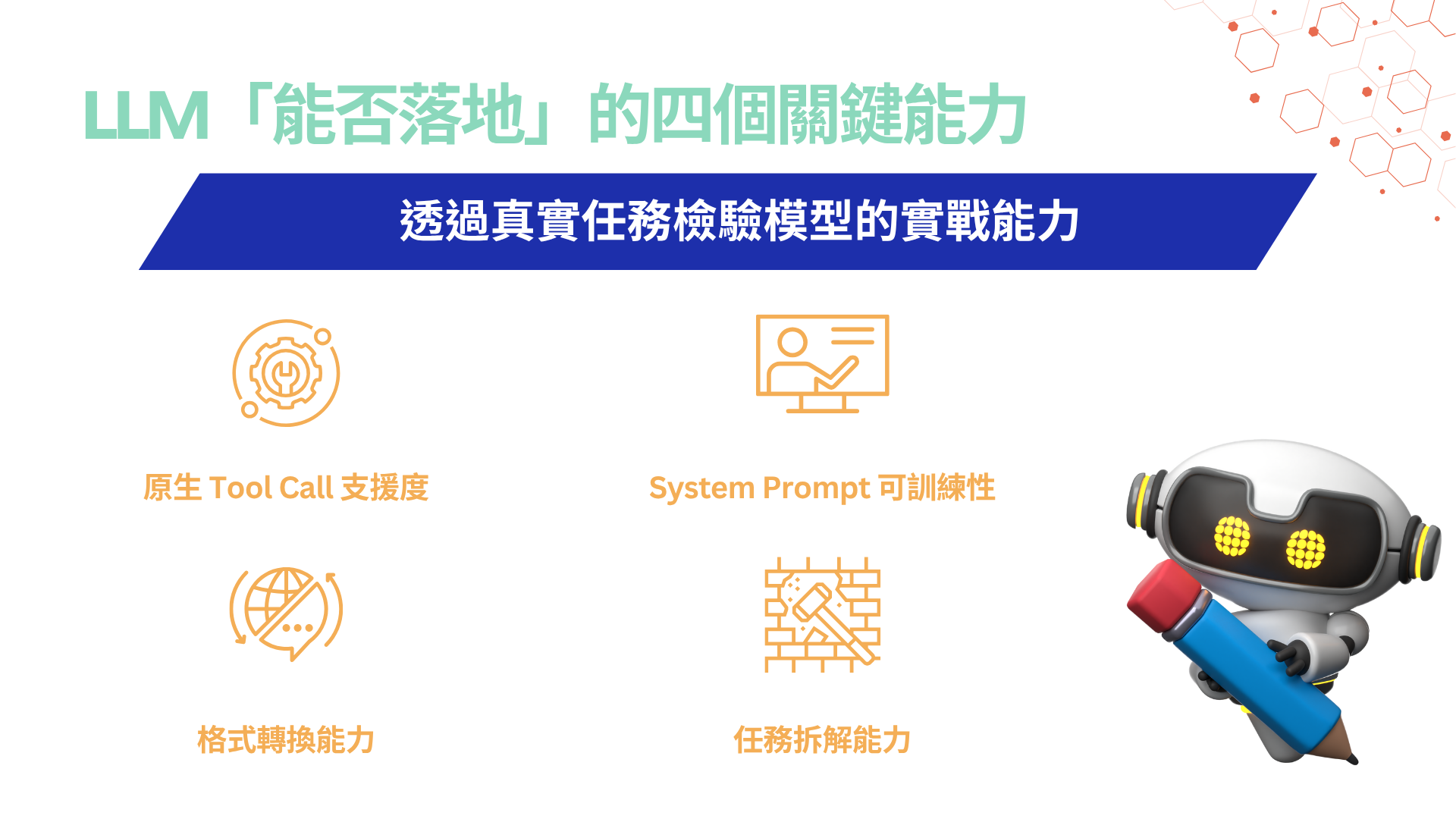
圖1:偲倢科技依據企業四個常見任務作為 LLM Tool call 評估標準;偲倢科技整理製圖
1. 原生 Tool Call 支援度
評估模型是否支援像 OpenAI function calling 或 HuggingFace tool spec 的原生工具呼叫介面。這類模型在實作上可直接與內部 API 或第三方服務對接,導入門檻最低。
2. System Prompt 可訓練性
2. System Prompt 可訓練性
針對非原生支援的模型,透過提示詞(prompt)教導其模仿 Tool Call 行為,評估其「可教性」。這對資源有限、需高度客製的企業至關重要。
3. 格式轉換能力
模擬將自然語言資料轉為 JSON 的能力,例如:
- 轉換顧客資訊、產品規格為結構化格式
- 處理多層嵌套(如品牌/型號/價格)
- 多筆條列資料(如商品或書籍清單)]
這項能力是串接 ERP、CRM、票務、訂單等系統的第一步。
4. 任務拆解能力
測試模型能否理解複雜敘述,並轉化為一組可執行的任務,例如:
4. 任務拆解能力
測試模型能否理解複雜敘述,並轉化為一組可執行的任務,例如:
- 安排日程(回診、會議)
- 設定提醒(交報告、準備簡報)
- 查詢資訊(天氣、行程空檔)
這些題目模擬智慧助理、企業 RPA、自動排程等應用場景,由 GPT-4o 評分拆解邏輯與完整性。
七款主流模型評比:小模型表現優異!
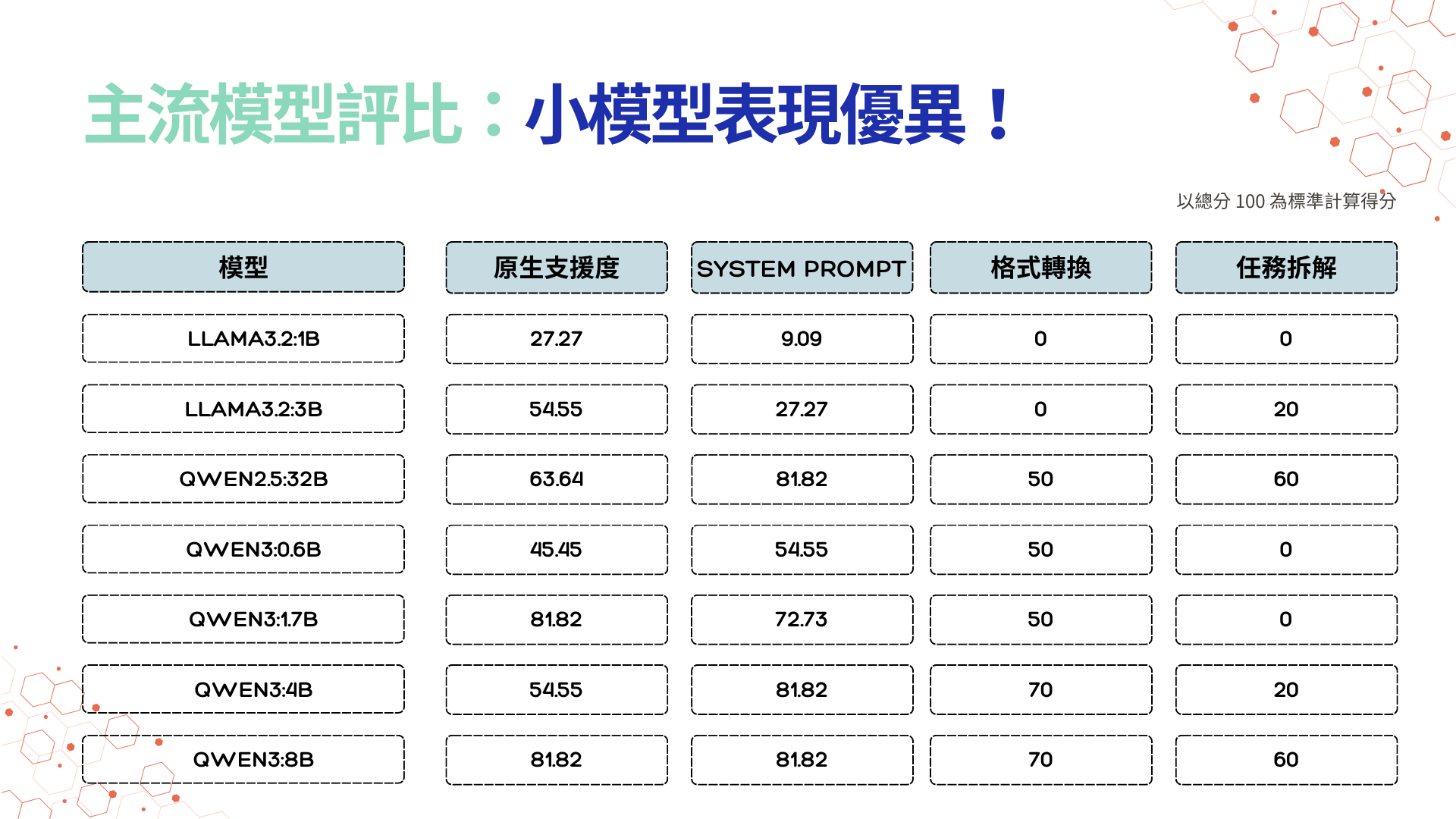
圖2:LLM 模型各參數實測效果;偲倢科技整理製圖
從結果看策略:為何小模型反而是企業導入的聰明選擇?

圖3: 偲倢科技建議Tool Call 是導入 LLM 的最基礎核心,選擇小參數模型將能讓整體資源更有效率;偲倢科技整理製圖
- Tool Call 是企業導入 LLM 的最小可行單位(MVP)
- 小模型 ≠ 小能力:中小企業的最佳起點
- Prompt 設計是未來部署效率的關鍵
Edgestar:讓企業真正落地 LLM 的 AI 基礎架構

圖4: 偲倢科技推出的 Edgestar 結合高效且彈性的硬體配置與直覺便利的模型管理平台;偲倢科技整理製圖
透過本次測試,我們觀察到 Tool Call 能力是企業應用生成式 AI 的起點。要讓 LLM 真正落地,選對模型之外,還要有能撐起運行與管理的基礎架構。Edgestar 正是為此而生的地端 AI 解決方案,幫助企業從測試走向部署,從模型選型走向穩定營運:
- 高效且彈性的硬體配置:Lite / Basic / Premium 三種方案,支援單卡推論、SFT 微調到大參數模型的全參數微調,依需求彈性調配,滿足不同企業規模與應用情境。
- 直覺便利的模型管理平台:內建 Edgestar Manager,整合推論服務、訓練流程與即時監控,支援多種推論引擎(vLLM、SGLang、NVIDIA NIM),相容 OpenAI API,一鍵部署、任務排程、GPU 自動分配,降低維護成本,提升落地效率。
Edgestar 不只是部署平台,更是企業邁向 LLM 生產力化的戰略夥伴。
📌 補充說明:語言對模型能力的影響
本次測試全數題目均以繁體中文進行,用來模擬台灣企業實際應用場景。需特別說明的是,部分模型(如 LLaMA 系列)以英文語料訓練為主,對繁體中文的理解與輸出能力相對有限,因此在 Tool Call 或任務拆解表現上可能受語言因素影響。
企業在評估模型選型時,應根據實際使用語言與任務語境進行驗證,避免僅以此測試分享作為決策依據。
📌 補充說明:語言對模型能力的影響
本次測試全數題目均以繁體中文進行,用來模擬台灣企業實際應用場景。需特別說明的是,部分模型(如 LLaMA 系列)以英文語料訓練為主,對繁體中文的理解與輸出能力相對有限,因此在 Tool Call 或任務拆解表現上可能受語言因素影響。
企業在評估模型選型時,應根據實際使用語言與任務語境進行驗證,避免僅以此測試分享作為決策依據。